
Arte creata dall’intelligenza artificiale
Un premio artistico alla Colorado State Fair è stato assegnato il mese scorso a un’opera che, all’insaputa dei giudici, è stata generata da un sistema di intelligenza artificiale (AI).
I social media hanno anche assistito a un’esplosione di immagini strane generate dall’intelligenza artificiale da descrizioni di testo, come “il volto di uno shiba inu confuso con il lato di una pagnotta su una panca da cucina, arte digitale”.
O forse “Una lontra marina nello stile di ‘Ragazza con l’orecchino di perla’ di Johannes Vermeer”:

Ti starai chiedendo cosa sta succedendo. Come persona che ricerca collaborazioni creative tra umani e AI, posso dirti che dietro i titoli dei giornali e i meme è in corso una rivoluzione fondamentale, con profonde implicazioni sociali, artistiche, economiche e tecnologiche.
Indice
Come siamo arrivati fino a qui
Si potrebbe dire che questa rivoluzione è iniziata nel giugno 2020, quando un’azienda chiamata OpenAI ha ottenuto una grande svolta nell’AI con la creazione di GPT-3, un sistema in grado di elaborare e generare linguaggio in modi molto più complessi rispetto ai precedenti sforzi. Puoi conversare con lui su qualsiasi argomento, chiedergli di scrivere un articolo di ricerca o una storia, riassumere il testo, scrivere una barzelletta e svolgere quasi ogni compito linguistico immaginabile.
Nel 2021, alcuni sviluppatori di GPT-3 si sono dedicati alle immagini. Hanno addestrato un modello su miliardi di coppie di immagini e descrizioni di testo, successivamente lo hanno utilizzato per generare nuove immagini da nuove descrizioni. Lo hanno chiamato sistema DALL-E e nel luglio 2022 hanno rilasciato una nuova versione molto migliorata, DALL-E 2.
Come GPT-3, DALL-E 2 è stato un importante passo avanti. Può generare immagini altamente dettagliate da input di testo in formato libero, comprese informazioni sullo stile e altri concetti astratti.
Ad esempio, qui le ho chiesto di illustrare la frase “Mind in Bloom” che unisce gli stili di Salvador Dalí, Henri Matisse e Brett Whiteley.

Entrano in scena i concorrenti
Dal lancio di DALL-E 2, sono emersi alcuni concorrenti. Uno è il DALL-E Mini gratuito ma di qualità inferiore (sviluppato in modo indipendente e ora ribattezzato Craiyon), che era una popolare fonte di contenuti di meme.

Più o meno nello stesso periodo, una società più piccola chiamata Midjourney ha rilasciato un modello che si avvicinava di più alle capacità di DALL-E 2. Sebbene sia ancora un po’ meno capace di DALL-E 2, Midjourney si è prestato a interessanti esplorazioni artistiche. È stato con Midjourney che Jason Allen ha generato l’opera d’arte che ha vinto il concorso Colorado State Art Fair.
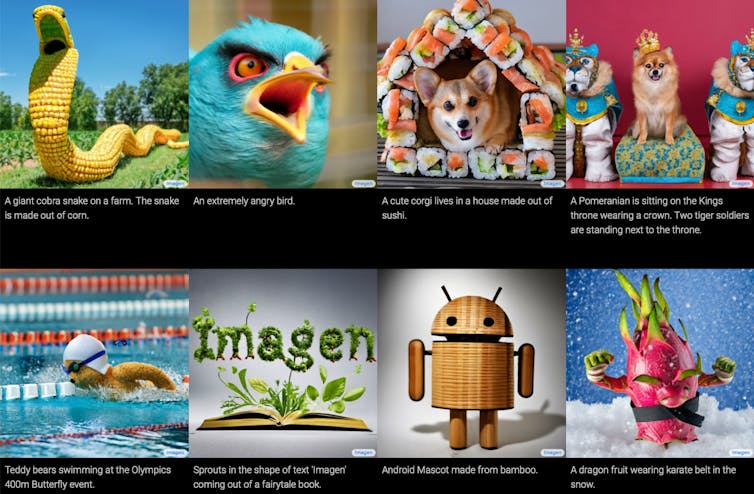
Anche Google ha un modello da testo a immagine, chiamato Imagen, che presumibilmente produce risultati molto migliori rispetto a DALL-E e altri. Tuttavia, Imagen non è stato ancora rilasciato per un uso più ampio, quindi è difficile valutare le affermazioni di Google.
Nel luglio 2022, OpenAI ha iniziato a capitalizzare l’interesse in DALL-E, annunciando che a 1 milione di utenti sarebbe stato concesso l’accesso a pagamento.
Ad agosto 2022 però è arrivato un nuovo contendente: Stable Diffusion.
Stable Diffusion non solo rivaleggia con DALL-E 2 nelle sue capacità, ma soprattutto è open source. Chiunque può utilizzare, adattare e modificare il codice a proprio piacimento.
Già nelle settimane successive al rilascio di Stable Diffusion, le persone hanno spinto il codice al limite di ciò che può fare.
Per fare un esempio: le persone si sono subito rese conto che, poiché un video è una sequenza di immagini, potevano modificare il codice di Stable Diffusion per generare video dal testo.
Un altro strumento affascinante creato con il codice di Stable Diffusion è Diffuse the Rest, che ti consente di disegnare un semplice schizzo, fornire un prompt di testo e generare un’immagine da esso.
La fine della creatività?
Cosa significa che puoi generare qualsiasi tipo di contenuto visivo, immagine o video, con poche righe di testo e un clic di un pulsante? Che ne dici di quando puoi generare un copione di film con GPT-3 e un’animazione di film con DALL-E 2?
E guardando più avanti, cosa significherà quando gli algoritmi dei social media non solo cureranno i contenuti per il tuo feed, ma li genereranno? E quando questa tendenza incontra il metaverso in pochi anni e i mondi di realtà virtuale vengono generati in tempo reale, solo per te?
Queste sono tutte domande importanti da considerare.
Alcuni ipotizzano che, a breve termine, ciò significhi che la creatività e l’arte umane sono profondamente minacciate.
Forse in un mondo in cui chiunque può generare qualsiasi immagine, i grafici come li conosciamo oggi saranno ridondanti. Tuttavia, la storia mostra che la creatività umana trova un modo. Il sintetizzatore elettronico non ha ucciso la musica e la fotografia non ha ucciso la pittura. Invece, hanno catalizzato nuove forme d’arte.
Credo che qualcosa di simile accadrà con la generazione dell’IA. Le persone stanno sperimentando l’inclusione di modelli come Stable Diffusion come parte del loro processo creativo.
Oppure utilizzando DALL-E 2 per generare prototipi di fashion design:
Un nuovo tipo di artista sta persino emergendo in quella che alcuni chiamano “promptology”, o “prompt engineering”. L’arte non sta nel creare pixel a mano, ma nel creare le parole che spingono il computer a generare l’immagine: una sorta di sussurro dell’AI.
Collaborare con l’IA
Gli impatti delle tecnologie di AI saranno multidimensionali: non possiamo ridurli a buoni o cattivi su un unico asse.
Nuove forme d’arte sorgeranno, così come nuove strade per l’espressione creativa. Tuttavia, credo che ci siano anche dei rischi.
Viviamo in un’economia dell’attenzione che prospera nell’estrarre il tempo sullo schermo dagli utenti; in un’economia in cui l’automazione guida il profitto aziendale ma non necessariamente l’aumento dei salari e in cui l’arte è mercificata come contenuto; in un contesto sociale dove è sempre più difficile distinguere il vero dal falso; in strutture sociotecniche che codificano troppo facilmente i pregiudizi nei modelli di AI che formiamo. In queste circostanze, l’AI può facilmente fare del male.
Come possiamo indirizzare queste nuove tecnologie di intelligenza artificiale in una direzione a vantaggio delle persone? Credo che un modo per farlo sia progettare un’AI che collabori con gli esseri umani, piuttosto che sostituirli.





