
Come funziona ChatGPT?
Vediamo molte opinioni su ChatGPT, ma alla fine cosa sappiamo? Solo che si tratta di una rete neurale artificiale con miliardi di parametri, capace di reggere una discussione ad alto livello, ma anche di cadere in rozze trappole tese da faceti internauti. Ne sentiamo parlare molto ma alla fine sappiamo molto poco su come funziona.
Propongo quindi di presentare i principali meccanismi su cui si basa ChatGPT e di mostrare che, se il risultato a volte è impressionante, i suoi meccanismi elementari sono intelligenti ma non proprio nuovi. Per fare ciò, rivediamo i diversi termini dell’acronimo “ChatGPT“.
Indice
T come trasformare
Un “trasformatore” è una rete neurale che beneficia dello stesso algoritmo di apprendimento delle reti profonde, che si è già dimostrato valido per l’addestramento di grandi architetture. Beneficia inoltre di due caratteristiche collaudate: da un lato, tecniche di “incorporamento lessicale” per la codifica delle parole; dall’altro, tecniche attenzionali per tener conto del fatto che le parole sono sequenziali.
Questo secondo punto è importante per interpretare il significato di ogni parola nel contesto dell’intera frase. La tecnica proposta dai trasformatori privilegia un approccio numerico e statistico, semplice da calcolare in modo massivo e molto efficace. Questo approccio consiste nell’apprendere, per ogni parola e dall’osservazione di numerosi testi, quali altre parole della frase devono essere “attenzionate” per individuare il contesto che può modificare il significato di questa parola. Ciò consente di abbinare una parola o sostituire un pronome con le parole della frase che rappresenta.
G come generativa
ChatGPT è in grado di generare linguaggio: gli presentiamo un problema e lui ci risponde con il linguaggio – è un “modello di linguaggio”.
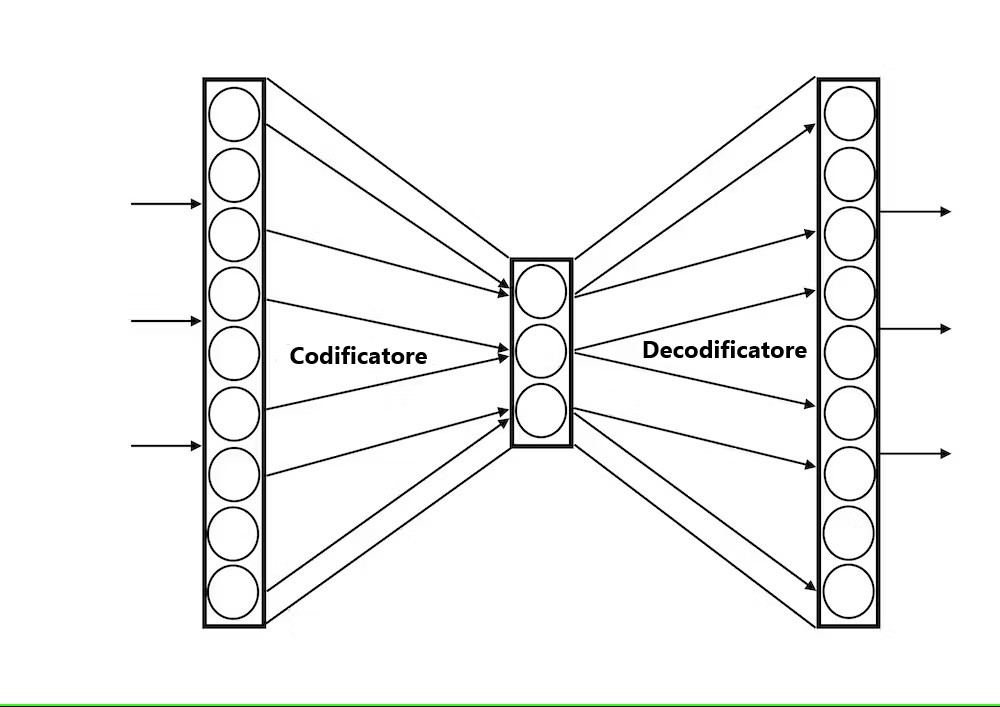
La capacità di apprendere un modello generativo con una rete neurale ha più di trent’anni: in un modello di autoencoder, l’output della rete viene addestrato a replicare il più fedelmente possibile il suo input (ad es. l’immagine di un volto), passando attraverso uno strato intermedio di neuroni, scelti per essere piccoli: se l’input può essere riprodotto attraverso una rappresentazione così compatta, è perché gli aspetti più importanti di questo input (il naso, gli occhi) sono mantenuti nella codifica di questo strato intermedio (ma i dettagli dovrebbero essere trascurati perché c’è meno spazio per rappresentare le informazioni). Vengono quindi decodificati per ricostruire un volto simile come output.
Utilizzato in modalità generativa, scegliamo un’attività casuale per lo strato intermedio e l’otteniamo come output, attraverso il decodificatore, qualcosa che sembrerà un volto con naso e occhi ma che sarà un esempio inedito del fenomeno in esame.
È ad esempio seguendo questo processo (con reti di grandi dimensioni) che riusciamo a creare deepfake, vale a dire effetti speciali molto realistici.
Se ora vogliamo generare fenomeni sequenziali (video o frasi), dobbiamo tenere conto dell’aspetto sequenziale del flusso di input. Questo può essere ottenuto con il meccanismo attenzionale sopra descritto, utilizzato in forma predittiva. In pratica, se mascheriamo una parola o se cerchiamo la parola successiva, possiamo prevedere questa parola mancante dall’analisi statistica degli altri testi.
L’efficacia di un semplice meccanismo di attenzione (che considera altre parole importanti nel contesto ma non esplicitamente il loro ordine) per elaborare l’aspetto sequenziale degli input è stata una scoperta importante nello sviluppo dei trasformatori (“Non hai bisogno di quell’attenzione” intitolato la pubblicazione corrispondente: “L’attenzione è tutto ciò di cui hai bisogno”), perché in precedenza i metodi preferiti utilizzavano reti più complesse, dette ricorrenti, il cui apprendimento è relativamente molto più lento e meno efficace; inoltre, questo meccanismo attenzionale si parallelizza molto bene, il che accelera ancora di più questo approccio.
P come in preaddestrato
L’efficacia dei trasformatori non è dovuta solo alla potenza di questi metodi, ma anche (e soprattutto) alla dimensione delle reti e alla conoscenza che queste ingeriscono per allenarsi.
I dettagli quantificati sono difficili da ottenere, ma si sente parlare di trasformatori con miliardi di parametri (di peso nelle reti neurali); per essere più efficaci si costruiscono in parallelo più meccanismi attenzionali (fino a un centinaio) per esplorare meglio le possibilità (si parla di attenzione “multitesta”), si può avere una successione di una decina di codificatori e decodificatori, ecc.
Ricorda che l’algoritmo di deep network learning è generico e si applica indipendentemente dalla profondità (e larghezza) delle reti; basta avere esempi a sufficienza per addestrare tutti questi pesi, il che rimanda ad un’altra caratteristica sproporzionata di queste reti: la quantità di dati utilizzati in fase di apprendimento.
Anche qui poche informazioni ufficiali, ma sembra che intere sezioni di internet siano risucchiate per partecipare alla formazione di questi modelli linguistici, in particolare tutta Wikipedia, i diversi milioni di libri che abbiamo trovato su internet (di cui versioni tradotti dagli umani sono molto utili per preparare i trasformatori di traduzione), ma molto probabilmente anche i testi che si possono trovare sui nostri social network preferiti.
Questa massiccia formazione si svolge offline, può durare settimane e utilizzare risorse computazionali ed energetiche eccessive (stimate in diversi milioni di dollari, per non parlare degli aspetti ambientali delle emissioni di CO₂ associate a questi calcoli).
Chatta come chattare
Ora siamo in una posizione migliore per presentare ChatGPT: è un agente conversazionale, costruito su un modello linguistico che è un trasformatore generativo pre-addestrato (GPT).
Le analisi statistiche (con approcci attentivi) dei corpora molto ampi utilizzati consentono di creare sequenze di parole con una sintassi di ottima qualità. Le tecniche di incorporamento lessicale offrono proprietà di prossimità semantica che danno frasi il cui significato è spesso soddisfacente.
Oltre a questa capacità di saper generare un linguaggio di buona qualità, un agente conversazionale deve anche saper conversare, ovvero analizzare le domande che vengono poste e fornire risposte pertinenti (o rilevare le insidie per evitarle). Ciò è stato intrapreso da un’altra fase di apprendimento offline, con un modello chiamato “InstructGPT”, che richiedeva la partecipazione di persone che interpretavano l’agente conversazionale o indicavano argomenti da evitare. In questo caso si tratta di “apprendimento per rinforzo”: ciò consente di selezionare le risposte in base ai valori loro attribuiti; è una sorta di semi-supervisione in cui gli umani dicono quello che avrebbero voluto sentire (o no).
ChatGPT fa ciò per cui è stato programmato
Le caratteristiche qui esposte permettono di capire che la funzione principale di ChatGPT è quella di prevedere la parola successiva più probabile tra i tanti testi che ha già visto e, tra le varie sequenze probabili, selezionare quelle che in genere gli umani preferiscono.
Questa sequenza di elaborazione può includere approssimazioni, quando vengono valutate le statistiche o nelle fasi di decodifica del modello generativo quando vengono costruiti nuovi esempi.
Questo spiega anche fenomeni di allucinazioni riportate, quando si chiede la biografia di qualcuno o dettagli su un’azienda e quando si inventa cifre e fatti. Quello che gli è stato insegnato a fare è costruire frasi plausibili e coerenti, non frasi veritiere. Non devi capire un argomento per saperlo parlare in modo eloquente, senza necessariamente dare alcuna garanzia sulla qualità delle tue risposte (ma anche gli umani sanno fare questo…).
Autore
Frédéric Alexandre, Inria





