
Il codice del genoma umano è finalmente completo
Quando lo Human Genome Project ha annunciato di aver completato il primo genoma umano nel 2003, è stato un risultato epocale: per la prima volta, il codice del DNA per la vita umana è stato decifrato. Ma c’era uno svantaggio, ed è che non era possibile raccogliere tutte le informazioni dal genoma. C’erano lacune, regioni non colmate, spesso ripetitive, che erano troppo confuse da mettere insieme.
Grazie ai progressi tecnologici per gestire queste sequenze ripetitive, gli scienziati hanno finalmente colmato queste lacune nel maggio 2021 e il primo genoma umano completo è stato ufficialmente pubblicato il 31 marzo 2022.
I pezzi del puzzle mancanti
Il botanico tedesco Hans Winkler coniò la parola “genoma” nel 1920, unendo la parola “gene” con il suffisso “-ome” (in italiano è genoma), che significa “insieme completo”, per descrivere la sequenza completa di DNA che contiene ogni cella. I ricercatori usano ancora questa parola un secolo dopo per riferirsi al materiale genetico che costituisce un organismo.
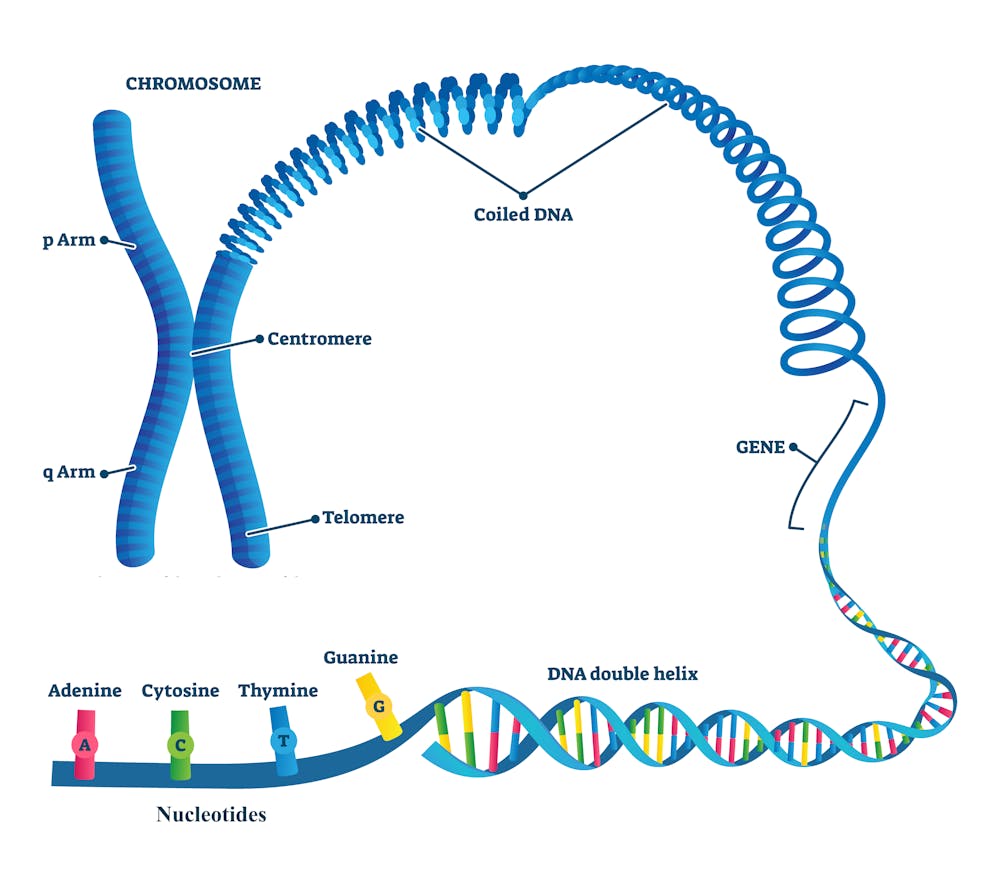
Un modo per descrivere l’aspetto di un genoma è confrontarlo con un libro di riferimento. In questa analogia, un genoma è un’antologia contenente le istruzioni del DNA per la vita. È costituito da un’ampia gamma di nucleotidi (lettere) che sono confezionati in cromosomi (filamenti). Ogni cromosoma contiene geni (paragrafi) che sono regioni del DNA che codificano per proteine specifiche che consentono a un organismo di funzionare.
Sebbene ogni organismo vivente abbia un genoma, le sue dimensioni variano da specie a specie. Un elefante usa la stessa forma di informazione genetica dell’erba che mangia e dei batteri nel suo intestino. Ma non esistono due genomi esattamente uguali. Alcuni sono brevi, come il genoma del batterio che vive negli insetti Nasuia deltocephalinicola, con solo 137 geni a 112.000 nucleotidi. Altri, come i 149 miliardi di nucleotidi nella pianta da fiore Paris japonica, sono così lunghi che è difficile avere un’idea di quanti geni contengano.
Tuttavia, i geni, come tradizionalmente intesi come tratti di DNA che codificano per le proteine, costituiscono solo una piccola parte del genoma di un organismo. Infatti, costituiscono meno del 2% del DNA umano.
Il genoma umano contiene circa 3 miliardi di nucleotidi e poco meno di 20.000 geni codificanti proteine, che rappresentano l’1% della lunghezza totale del genoma.
Il restante 99% sono sequenze di DNA non codificanti che non producono proteine. Alcuni sono componenti regolatori che fungono da quadro elettrico per controllare il funzionamento di altri geni. Altri sono pseudogeni o relitti genomici che hanno perso la loro capacità di funzionare.
E più della metà del genoma umano è ripetitivo, con più copie di sequenze quasi identiche.
Cos’è il DNA ripetitivo?
La forma più semplice di DNA ripetitivo è costituita da blocchi di DNA ripetuti più e più volte in tandem, chiamati satelliti. Sebbene la quantità di DNA satellite in un dato genoma vari da persona a persona, tendono a raggrupparsi verso le estremità dei cromosomi in regioni chiamate telomeri. Queste regioni proteggono i cromosomi dalla degradazione durante la replicazione del DNA. Si trovano anche ai centromeri dei cromosomi, una regione che aiuta a mantenere intatte le informazioni genetiche quando le cellule si dividono.
I ricercatori non comprendono ancora completamente tutte le funzioni del DNA satellitare. Ma poiché forma schemi unici in ogni persona, i biologi forensi e i genealogisti usano questa impronta genomica per abbinare i campioni della scena del crimine e tracciare l’ascendenza. Più di 50 malattie genetiche sono legate a variazioni del DNA satellite, inclusa la malattia di Huntington.
Un altro tipo abbondante di DNA ripetitivo sono gli elementi o le sequenze trasponibili che possono muoversi intorno al genoma.
Alcuni scienziati li hanno descritti come DNA “egoisti” perché possono essere inseriti ovunque nel genoma, indipendentemente dalle conseguenze. Con l’evoluzione del genoma umano, molte sequenze trasponibili hanno raccolto mutazioni, reprimendo la loro capacità di muoversi per evitare rotture dannose. Ma è probabile che alcuni continuino a muoversi. Ad esempio, le inserzioni di elementi trasponibili sono legate a diversi casi di emofilia A, una malattia emorragica genetica.
Ma gli elementi trasponibili non sono solo dirompenti. Possono avere funzioni regolatorie che aiutano a controllare l’espressione di altre sequenze di DNA. Se concentrati nei centromeri, possono anche aiutare a mantenere l’integrità dei geni critici per la sopravvivenza cellulare.
Possono anche contribuire all’evoluzione. I ricercatori hanno recentemente scoperto che l’inserimento di un elemento trasponibile in un gene importante per lo sviluppo potrebbe essere il motivo per cui alcuni primati, compreso l’uomo, non hanno più la coda. I riarrangiamenti cromosomici dovuti ad elementi trasponibili sono addirittura legati alla genesi di nuove specie come i gibboni del sud-est asiatico e i wallaby dell’Australia.
Completa il puzzle genomico
Fino a poco tempo fa, molte di queste complesse regioni potevano essere paragonate al lato opposto della luna: si sapeva che esistevano, ma non si vedevano.
Quando il Progetto Genoma Umano è stato lanciato per la prima volta nel 1990, i limiti tecnologici hanno impedito la piena scoperta di regioni ripetitive del genoma. La tecnologia di sequenziamento disponibile poteva leggere solo circa 500 nucleotidi alla volta e questi brevi frammenti dovevano sovrapporsi per ricreare la sequenza completa. I ricercatori hanno utilizzato questi segmenti sovrapposti per identificare i successivi nucleotidi nella sequenza, espandendo gradualmente l’assemblaggio del genoma un frammento alla volta.
Queste regioni di spazi vuoti ripetuti erano come mettere insieme un puzzle di 1.000 pezzi di un cielo nuvoloso: quando tutti i pezzi sono uguali, come fai a sapere dove inizia una nuvola e finisce un’altra? Con tratti quasi identici che si sovrappongono in molti punti, il sequenziamento frammentario dell’intero genoma è diventato impossibile. Milioni di nucleotidi sono stati nascosti nella prima iterazione del genoma umano.
Da allora, le patch di sequenza hanno gradualmente riempito le lacune nel genoma umano. E nel 2021, il Consorzio Telomere-to-Telomere (T2T), un consorzio internazionale di scienziati che lavora per completare un assemblaggio end-to-end del genoma umano, ha annunciato che tutte le lacune rimanenti sono state finalmente colmate.
Ciò è stato reso possibile da una migliore tecnologia di sequenziamento, in grado di leggere sequenze più lunghe di migliaia di nucleotidi. Con più informazioni per inserire sequenze ripetitive in un’immagine più ampia, è diventato più facile identificare il loro posto corretto nel genoma. Come semplificare un puzzle da 1.000 pezzi in un puzzle da 100 pezzi, le lunghe sequenze di lettura hanno permesso per la prima volta di assemblare grandi regioni ripetitive.
Grazie alla potenza crescente della tecnologia di sequenziamento del DNA a lunga lettura, i genetisti sono pronti a esplorare una nuova era della genomica, svelando per la prima volta complesse sequenze ripetitive in popolazioni e specie. E un genoma umano completo e privo di lacune è una risorsa inestimabile per i ricercatori per studiare le regioni ripetitive che modellano la struttura e la variazione genetica, l’evoluzione delle specie e la salute umana.
Ma un genoma completo non raccoglie tutto. Gli sforzi continuano per creare diversi riferimenti genomici che rappresentino pienamente la popolazione umana e la vita sulla Terra. Con riferimenti genomici più completi, “telomere per telomere”, la comprensione degli scienziati della materia oscura ripetitiva del DNA diventerà più chiara.
Gabrielle Hartley, Università del Connecticut




{kind=link}